| Japanese | English |

第25回LSIデザインコンテスト・イン沖縄 設計仕様書 - 3-1
3-1. 強化学習の一連の流れ
基本的な学習方法はQ学習と同様であり「環境」,「エージェント」,「行動」,「報酬」の4要素を活用して学習を行う. 環境:エージェントのいる環境 エージェント:行動する主体 行動:エージェントが行う行動 報酬:行動によって与えられる褒美 深層強化学習の一連の流れとイメージ図を以下のFig 1,Fig 2に示す.
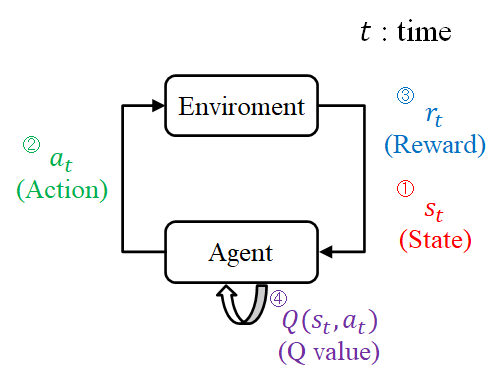
Fig 1 : 深層強化学習の一連の流れ
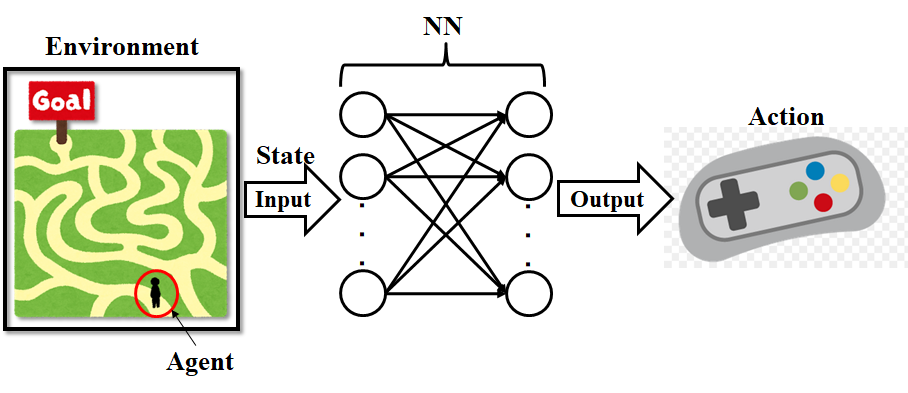
Fig 2 : 深層強化学習のイメージ図
ここでは,深層学習アルゴリズムにニューラルネットワーク(Neural Network : NN)を用いた例で説明する.
基本的には以下のステップを繰り返し行うことで学習が進められる.
- タイムステップt毎に,エージェントは環境から現在の状態を観測し,NNへの入力として与える.
- "1"で得られた入力に対するNNの出力を参考にエージェントは行動を決定する.
- エージェントは行動した結果の良し悪しを報酬として受け取る.
- 報酬を基に誤差関数を作成し,NNの重み・バイアスを更新する.
Copyright (C) 2021-2022 LSI Design Contest. All Rights Reserved.