| Japanese | English |

第24回LSIデザインコンテスト・イン沖縄 設計仕様書 - 3-1
3-1. 強化学習の一連の流れ
強化学習では「環境」,「エージェント」,「行動」,「報酬」の4要素を活用して学習を行う. 環境:エージェントのいる環境 エージェント:行動する主体 行動:エージェントが行う行動 報酬:行動によって与えられる褒美 強化学習の一連の流れを以下の図1に示す.
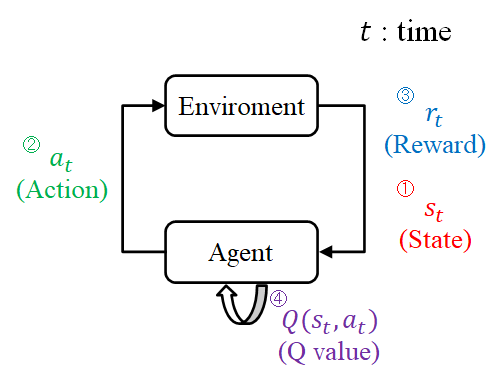
Fig 1 : 強化学習の一連の流れ
- タイムステップt毎に,エージェントは環境から現在の状態を観測する.
- エージェントは自分が今いる状態の中で取り得る行動の中で,最も価値の高い(Q値が最も高い)行動を選択する.
- エージェントは行動した結果の良し悪しを報酬として受け取る.
- 状態st,行動atにおけるQ値(行動の価値の指標)を更新する.
Copyright (C) 2020-2021 LSI Design Contest. All Rights Reserved.