| Japanese | English |

第24回LSIデザインコンテスト・イン沖縄 設計仕様書 - 4-1
4-1.Q値表
強化学習の目的は,行動の価値の指標であるQ値を更新していくことで,最終的にエージェントが得られる報酬が最大限となるようなQ値の表を完成させること,
と言い換えることもできる.表1に例題における未学習状態のQ値表を示す.
※初期値はランダムで生成,S25はゴールとなっており,それ以上行動する必要はないため0と設定している.
Table 1 : 未学習状態のQ値表
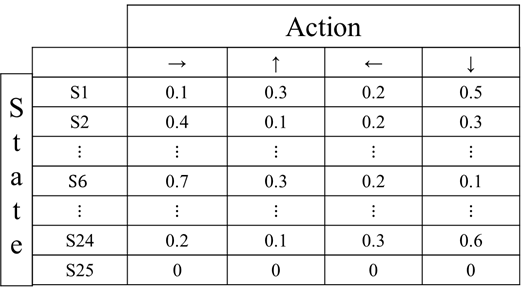
表1は各状態におけるそれぞれの行動の価値を数値化して示してある.例えば,
S1においては「→」,「↑」,「←」,「↓」に進む価値がそれぞれ0.1,0.3,0.2,0.5となっており,
最も価値の高い行動は「↓」に進むことだということが分かる.
本例題では,強化学習を通じてQ値表を適切な形へと完成させていく.
Copyright (C) 2020-2021 LSI Design Contest. All Rights Reserved.