| Japanese | English |

24th LSI Design Contests-in Okinawa Design Specification - 4-2
4-2.Q - Learning
There are several methods for updating Q-value, and this example deals with Q-Learning (Following: Q Learning and Notation) which is one of them. The equation for Q value update in Q learning is shown below.
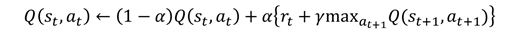
In the above equation, α, γ and r are hyperparameters.
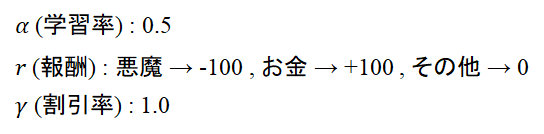
- The flow of Q value renewal is examined using an actual example.
- The agent grasps that its current state is S1.
- From Table 1, the action to advance to "↓" with the highest Q value is selected.
- Since the transition destination becomes S6, a value of 0 is received as a reward.
- Q value is updated based on the reward.
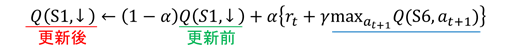
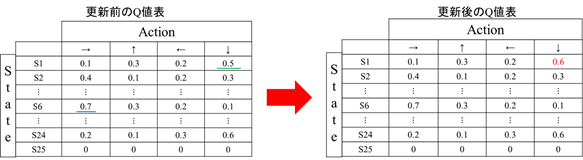
By repeating the above 1 ~ 5, the Q value table approaches the optimum one.
Copyright (C) 2020-2021 LSI Design Contest. All Rights Reserved.